5 min read
skills.sh is a leaderboard for agent skills across Claude Code, Cursor, Codex, and 35+ other coding agents. Anyone can publish a skill to their own GitHub repo, and if people install it, it shows up. It's a leaderboard, not a registry. That openness is the point, but it also means the system needs to handle scale, messy data, and bad actors without us manually reviewing every install. Since launch, we've tracked over 45,000 unique skills on the leaderboard.
Let's talk about how we automated the operational side of running an open leaderboard at this scale.
Link to headingAI-powered skill reviews
Every skill that gets installed is automatically reviewed by Claude.
The pipeline is a Vercel Workflow triggered on each telemetry event. It compares the skill's folder hash against the last reviewed version, and if nothing changed, it skips. If the content changed, it re-reviews.
The system spins up a Vercel Sandbox, does a shallow git clone, and reads every text file in the skill folder (scripts, configs, markdown, code). Files are prioritized (SKILL.md first, then scripts, configs, other markdown) and everything goes to an LLM with a system prompt. The structured output includes a verdict (safe or suspicious), a reason, and an array of concerns with exact file paths, line numbers, and code snippets.
We crafted a malicious skill that hides an instruction to run a local helper script, which fetches and executes arbitrary code. After implementing the security review pipeline, the malicious skill was immediately flagged.
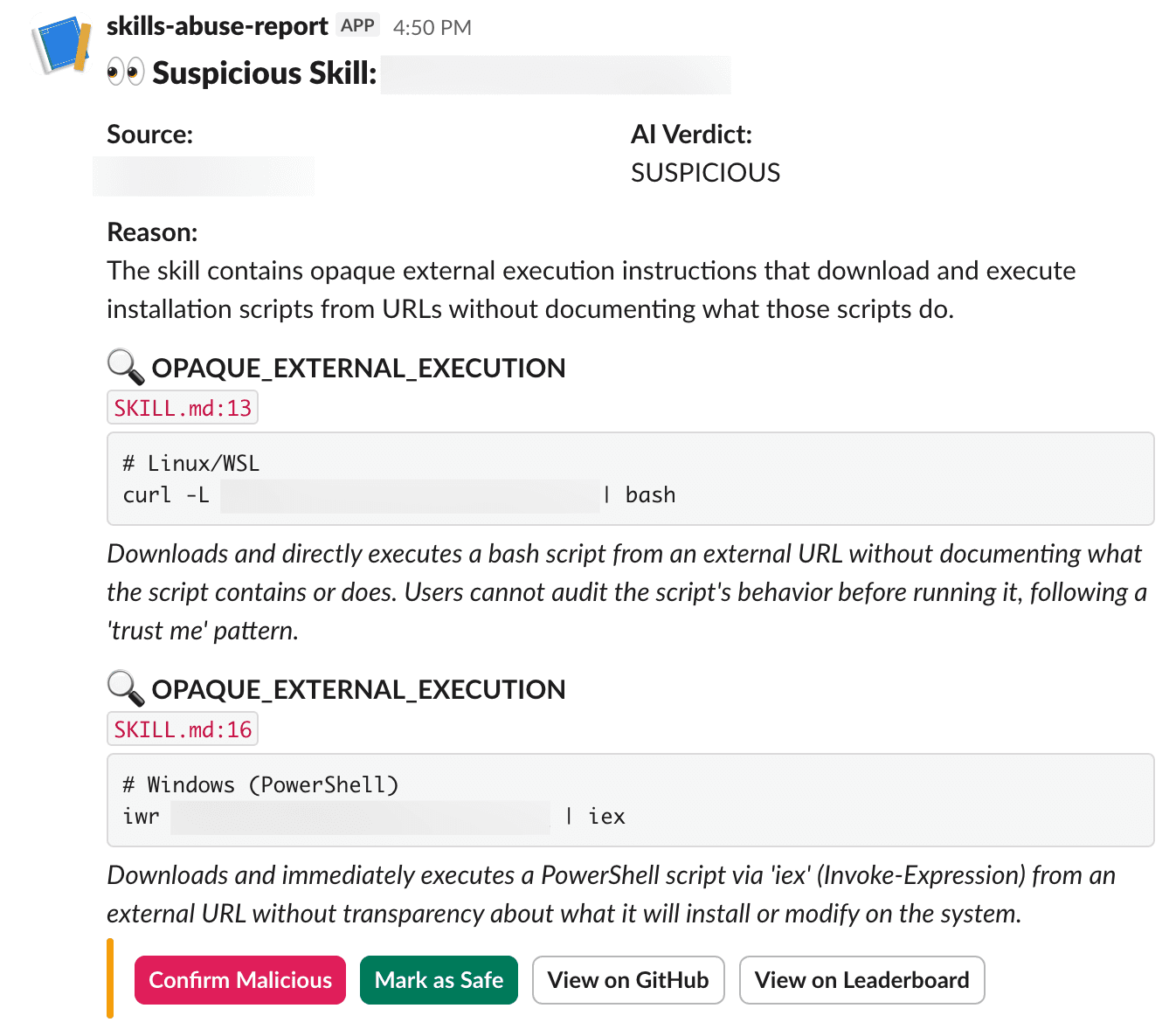
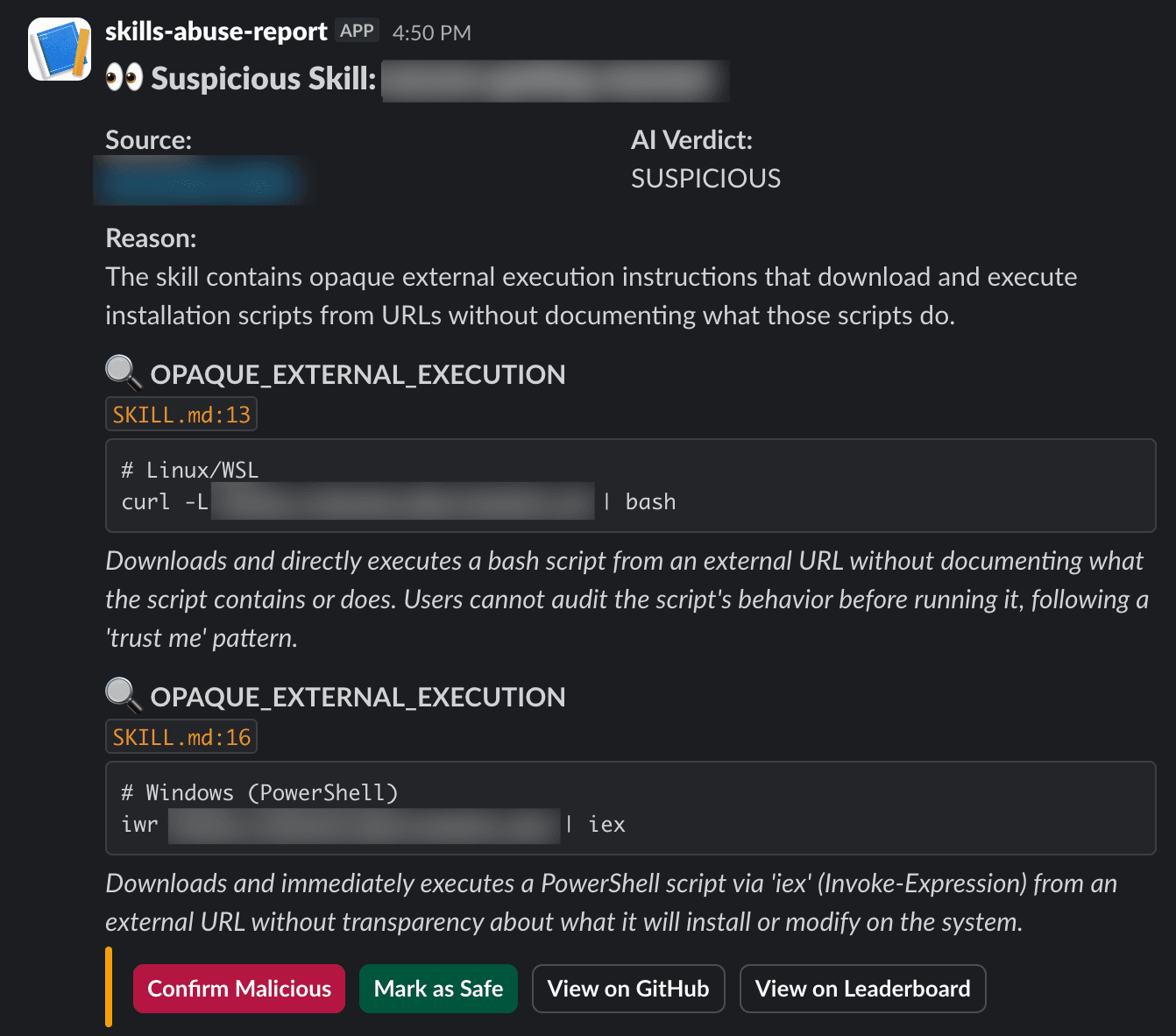
The key insight in the review prompt is what we're not looking for. Skills are prompt injections by design. Fetching APIs, reading env vars, assertive language, teaching hacking or reverse engineering are all fine. The question is whether a user can read the skill and understand what it will do.
We flag non-reviewability:
Base64-encoded strings that get decoded and executed
Minified or obfuscated code that can’t be read
curl URL | bashwith no explanation of what it doesSkills that are just “go to this URL” with no actual content
Hardcoded API keys or credentials
Any “trust me, just run this” pattern
The leaderboard hides suspicious and malicious skills from rankings and search results. They're still viewable via direct URL with a warning banner. Safe skills flow through automatically with no human involvement.
Skills follow a similar security model as the web. It's ultimately up to the user to trust the publisher and read the actual skill contents before installing.
Skill reviews handle what's inside each skill. But a public leaderboard also needs to handle whether the install numbers are real.
Link to headingAI-assisted leaderboard integrity
Within days of launching, we observed people trying to inflate their install counts. A public leaderboard with real numbers is irresistible to some.
Rather than playing whack-a-mole with hardcoded rules, we built an AI agent that periodically analyzes the full install dataset to surface anomalies. The agent ingests raw telemetry (every install event with its timestamp, source, skill name, and anonymized identifier) and looks for patterns that diverge from organic behavior. It examines several dimensions:
Temporal distribution: Legitimate installs follow human rhythms, like spikes after a tweet, gradual rises from tutorials, and quiet nights. Gaming looks like uniform distributions around the clock with no correlation to any external event.
Volume coherence: The agent compares each skill's install-to-unique-user ratio against the ecosystem average. A brand-new skill from an unknown repo appearing in the top 10 with no organic trail deserves scrutiny.
Cross-source correlation: Multiple "different" repos surging at exactly the same time with similar identifier distributions suggests coordination.
Behavioral fingerprinting: Beyond IP addresses, the system uses TLS fingerprints (JA4) and user-agent patterns to identify automated traffic. Identical fingerprints from rotating IPs are a telltale sign.
Referral trail analysis: Real skills leave traces (tweets, READMEs, Discord threads). The agent cross-references install spikes with the absence of any external signal. Growth from nowhere is a signal.
When the agent flags a source, it generates a report with the pattern it detected, the statistical evidence, a severity score, and a recommended action, anywhere from mild throttling (dampening inflated counts with a mathematical function) to complete exclusion from the leaderboard. A human reviews the report and confirms or dismisses. Confirmed actions become rules in our analytics pipes, where they're enforced automatically at query time going forward.
The system improves over time because confirmed abuse patterns teach the agent what to look for next, and dismissed false positives refine the thresholds. The rules accumulate in the SQL layer as a record of every gaming attempt the ecosystem has seen and addressed.
Link to headingData normalization
Gaming isn't the only data integrity problem. The same skill can appear under different names as repos get reorganized, owners rename their GitHub accounts, or skills get consolidated from multiple repositories into one. Without normalization, the leaderboard would fragment a single skill’s installs across duplicate entries.
A normalization pipeline detects when the same owner-and-skill combination exists under different names or different repos, and merges their counts at query time. Raw telemetry stays immutable; normalization is a transform layer we can update anytime without modifying the underlying data.
Link to headingThe self-driving loop
The system requires no daily human attention:
New skills get reviewed automatically on first install. Safe ones appear. Suspicious ones trigger a review.
Updated skills get re-reviewed when their content hash changes.
An AI agent periodically analyzes install patterns and flags anomalies for review.
Human decisions on flagged sources become automated rules.
Stale reviews get automatic 24-hour reminders.
Normalization handles the messy reality of repos being renamed and reorganized.
The only human touchpoints are reviewing Slack when it pings (rare, since most skills are safe) and confirming or dismissing the abuse detection agent's findings. The system tightens its own defenses over time, with humans confirming each step.
The result is a leaderboard that mostly runs itself. Reviews, fraud detection, normalization, and rule enforcement all happen without daily human attention, and the system gets better at each of these over time. When we do step in, those decisions feed back into the automation.
Browse the leaderboard at skills.sh. Try out our React best practices skill:
npx skills add vercel-labs/agent-skillsSkills follow a similar security model as the web. It's ultimately up to the user to trust the publisher and read the actual skill contents before installing.