The choice of a database can significantly influence the performance, functionality, and scalability of your application. This guide provides a deep dive into the differences between two important paradigms, SQL and NoSQL, each with a unique set of benefits suited for particular use cases.
Structured Query Language (SQL) is a standardized language for managing and querying data in relational databases. Such databases organize data into tables consisting of rows and columns. Each table typically represents a distinct entity, and SQL helps define and manipulate relationships between these entities.
The query language is the means by which you interact with the data. You can perform various operations like adding new data (INSERT), updating existing data (UPDATE), deleting data (DELETE), or retrieving data (SELECT) using different queries.
Various database management systems like MySQL and PostgreSQL use SQL as their query language.
SQL databases prioritize accuracy, integrity, and relationship enforcement, often encapsulated in a structured, predefined schema.
They were primarily designed for vertical scalability, which means enhancing the server's hardware capabilities for improved performance. For example, you could upgrade the server with a faster CPU, more RAM, or faster storage.
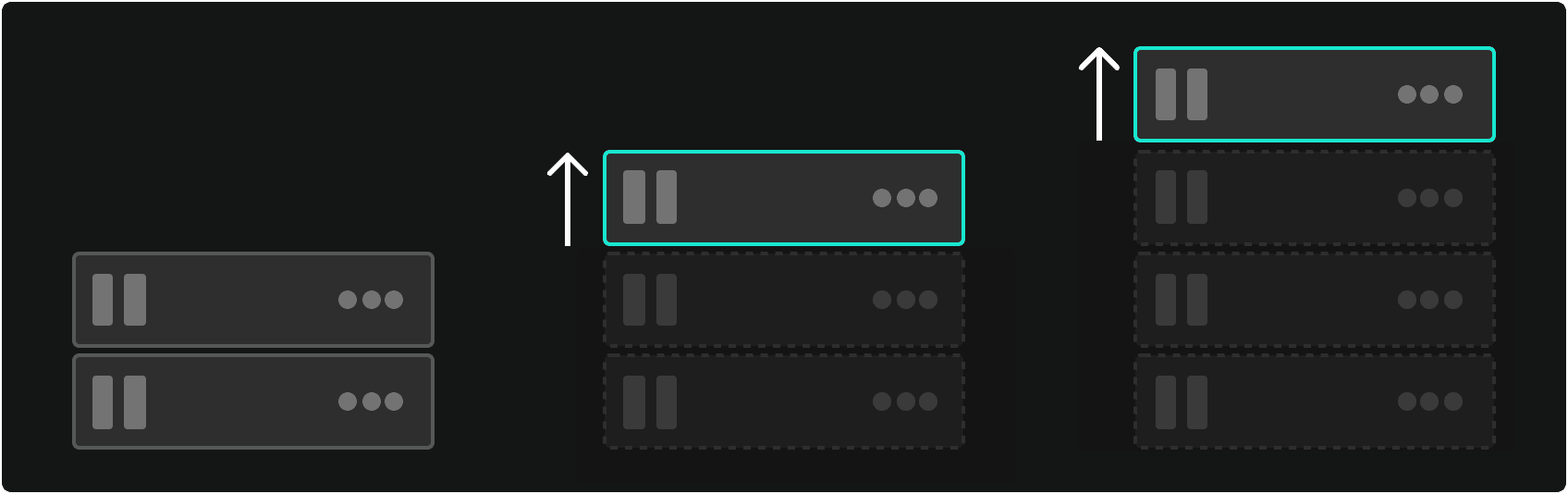
However, these databases also support horizontal scaling through data sharding. This involves partitioning the database into smaller, more manageable pieces; shards. Shards can be distributed across a multitude of servers and enable the system to handle increased traffic and data volumes without compromising performance.
SQL databases are ACID compliant. This means that they adhere to a set of properties— Atomicity, Consistency, Isolation, Durability — which strengthen data integrity and transaction management, which is necessary for applications in which data accuracy and reliability are crucial.
- Atomicity: Every transaction is treated as a singular unit, ensuring complete success or failure.
- Consistency: Only valid data is written to the database, maintaining system integrity.
- Isolation: Concurrent transactions are processed in a way that the outcome is the same as if they were processed individually, preventing potential interference.
- Durability: Committed transactions persist, even during system failures.
Applications where data consistency and accuracy are paramount, like financial or medical record systems, often opt for SQL databases.
NoSQL ("Not Only SQL") databases provide more flexibility in handling unstructured or semi-structured data. These databases don't require a fixed schema.
Querying methods can vary among NoSQL databases. MongoDB, for example, uses a method-based query language that is JavaScript-like in its syntax:
NoSQL databases are optimized for specific tasks that require more flexibility, like document storage, key-value pairs, or graph-based relationships. They prioritize horizontal scalability, which is achieved through techniques like sharding or partitioning — distributing data across multiple servers to accommodate more traffic. This design caters to high-throughput, web-scale applications dealing with large data volumes.
Unlike SQL where data normalization necessitates separate tables, NoSQL databases simplify this by allowing related data to be stored together, reducing query complexity.
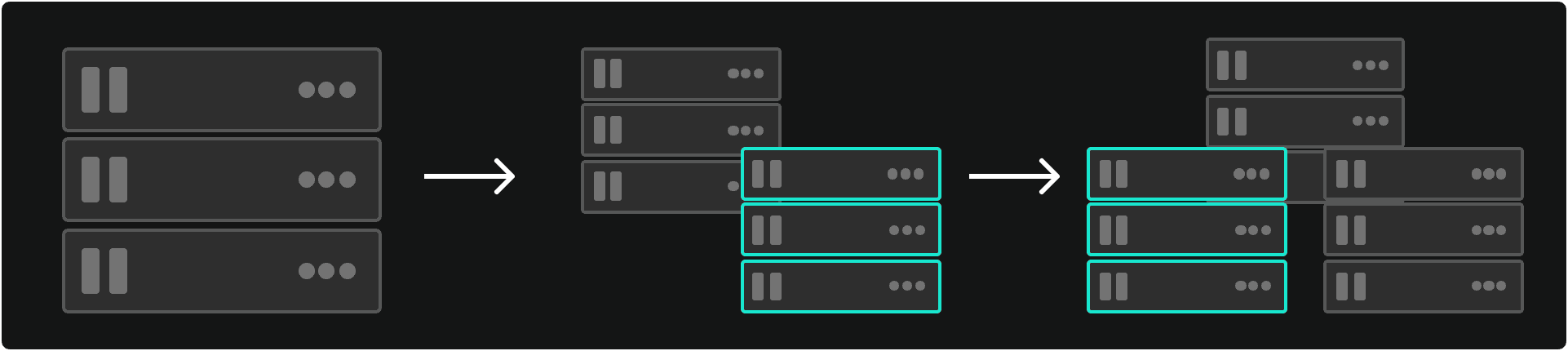
Horizontal sharding involves distributing rows of data across multiple servers, so each server contains all the necessary columns but for a subset of users. This approach is great for NoSQL databases, as it allows them to distribute large datasets across multiple servers or clusters, enhancing horizontal scalability.
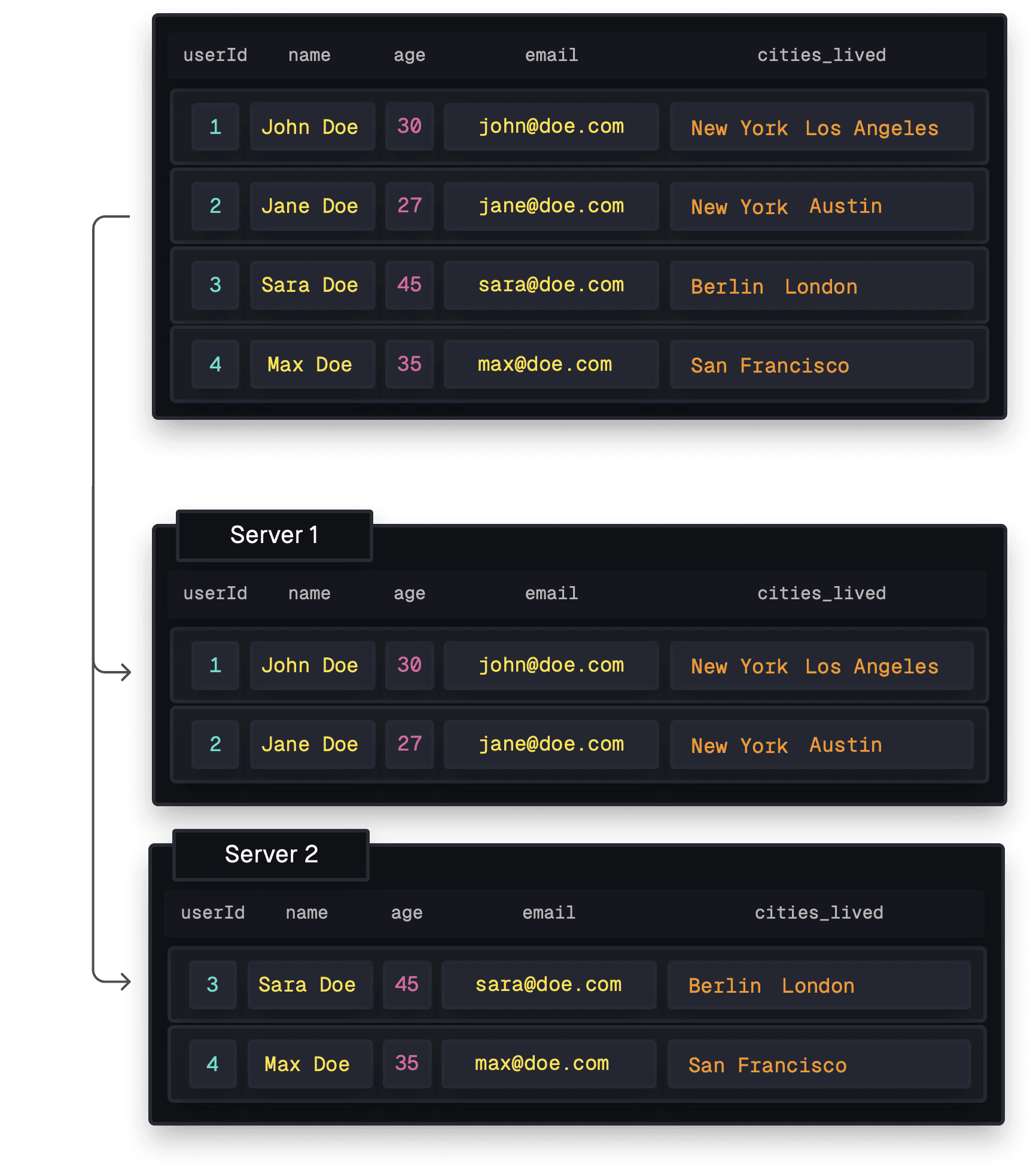
However, the fact that NoSQL databases can store related data together can be less space-efficient and can make aggregations more challenging.
In SQL, aggregations and JOIN operations are more straightforward, with structured, normalized data facilitating complex queries. In NoSQL, however, you might need to create an index to support more complex aggregations. It's a trade-off between query complexity and scalability.
NoSQL databases usually follow the CAP theorem:
- Consistency: Similar to ACID’s consistency, ensuring data remains consistent post-transactions across a distributed system.
- Availability: The system remains operational for both reads and writes, even during network partitions.
- Partition Tolerance: The system operates despite network partitioning, a common occurrence in distributed systems due to various network issues.
Network partitioning is a communication breakdown within a distributed system—imagine a bunch of interconnected computers suddenly losing touch with some others in the group. This scenario is common in distributed setups due to network-related issues such as router failures, switch failures, or other network hardware problems.
According to the CAP theorem, databases can guarantee only two of these three attributes during network partitioning.
Trade-offs among these properties depend on system requirements. For example, prioritizing consistency and partition tolerance may result in intermittent unavailability for reads and writes.
In another guide, we explore the differences between popular SQL and NoSQL choices like MySQL, PostgreSQL, and MongoDB.